

Web Scraping in Golang
Web Scraping in Golang using Fiber Framework and Colly Framework

I am a Developer experienced in building Web Apps and CLI using Golang. I'm also experienced in Laravel development
Introduction
Every developer uses web scraping as a necessary tool at some time in their career. Therefore, developers must understand web scrapers and how to create them.
In this blog, we will be covering the basics of web scraping in Go using the Fiber and Colly frameworks. Colly is an open-source web scraping framework written in Go. It provides a simple and flexible API for performing web scraping tasks, making it a popular choice among Go developers. Colly uses Go's concurrency features to efficiently handle multiple requests and extract data from websites. It offers a wide range of customization options, including the ability to set request headers, handle cookies, follow redirects, and more
We'll start with a simple example of extracting data from a website and then move on to more advanced topics like customizing the scraping process and setting request headers. By the end of this blog, you'll have a solid understanding of how to build a web scraper using Go and be able to extract data from any website.
Prerequisites
To continue with the tutorial, firstly you need to have Golang and Fiber installed.
Installations :
Getting Started
Let's get started by creating the main project directory Go-Scraper by using the following command.
(🟥Be careful, sometimes I've done the explanation by commenting in the code)
mkdir Go-Scraper //Creates a 'Go-Scraper' directory
cd Go-Scraper //Change directory to 'Go-Scraper'
Now initialize a mod file. (If you publish a module, this must be a path from which your module can be downloaded by Go tools. That would be your code's repository.)
go mod init github.com/<username>/Go-Scraper
To install the Fiber Framework run the following command :
go get -u github.com/gofiber/fiber/v2
To install the Colly Framework run the following command :
go get -u github.com/gocolly/colly/...
Now, let's make the main.go in which we are going to implement the scraping process.
In the main.go file, the first step is to initialize a new Fiber app using the fiber.New() method. This creates a new instance of the Fiber framework that will handle the HTTP requests and responses.
Next, we define a new endpoint for the web scraper by calling the app.Get("/scrape", ...) method. This creates a new GET endpoint at the /scrape route, which will be used to trigger the web scraping process.
package main
import (
"fmt"
"github.com/gofiber/fiber/v2"
)
func main() {
app := fiber.New() // Creating a new instance of Fiber.
app.Get("/scrape", func(c *fiber.Ctx) error {
return c.SendString("Go Web Scraper")
})
app.Listen(":8080")
}
After running the go run main.go command the terminal will look like this,
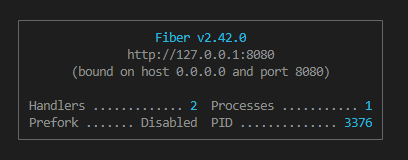
Let's create a new instance of the Colly collector using the colly.NewCollector() method. The collector is responsible for visiting the website, extracting data, and storing the results.
collector := colly.NewCollector(
colly.AllowedDomains("j2store.net"),
)
collector.OnRequest(func(r *colly.Request) {
fmt.Println("Visiting", r.URL)
})
The colly.AllowedDomains property in the Colly framework is used to restrict the domains that the web scraper is allowed to visit. This property is used to prevent the scraper from visiting unwanted websites. For this blog, we are going to use this site which contains sample data and the domain is j2store.net .
The Colly collector can be configured in a variety of ways to customize the web scraping process. In this case, we define a request handler using the collector.OnRequest(...) method. This handler is called each time a request is made to the website, and it simply logs the URL being visited.
Now, to extract data from the website, we are going to use the collector.OnHTML(...) method to define a handler for a specific HTML element.
This is how the sample data on the site looks,
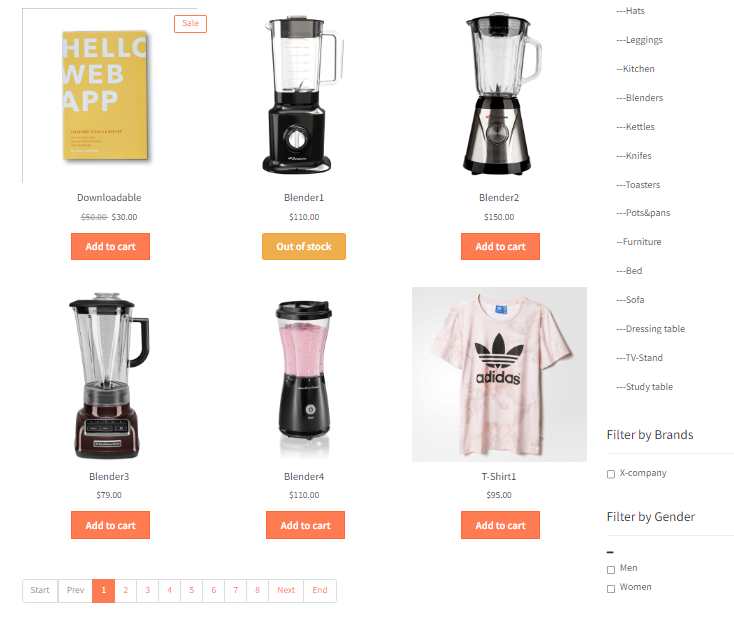
Here are some product images, their names and their price. We are just going the extract their names, image URL and prices.
So, let's create a struct item containing these three fields i.e. Name, Price, Image URL. The data type is defined as a string. JSON field is added as we are going to return all the data in JSON.
type item struct {
Name string `json:"name"`
Price string `json:"price"`
ImgUrl string `json:"imgurl"`
}
Now, Let's work on the OnHTML() callback.
collector.OnHTML("div.col-sm-9 div[itemprop=itemListElement] ", func(h *colly.HTMLElement) {
item := item{
Name: h.ChildText("h2.product-title"),
Price: h.ChildText("div.sale-price"),
ImgUrl: h.ChildAttr("img", "src"),
}
items = append(items, item)
})
Here, inside the OnHTML() function firstly, we added something inside quotes that is the parent element it's a CSS selector, inside this div tags all the products are added. You can see it on the page by Inspect Element and hovering over the product just like the way I did in the image below. This means that whenever this parent element comes then this OnHTML callback must be called.
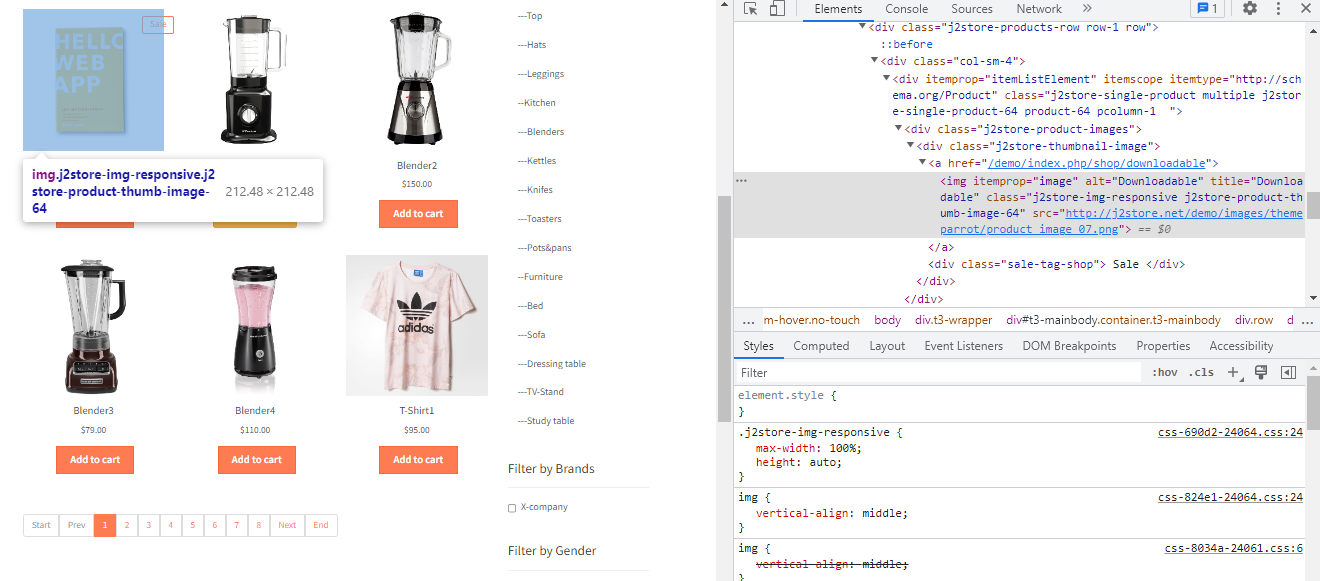
We've used the child element to get only the required data i.e the Name, Price and the ImgUrl. You can see these Child elements just the way we did for the parent element.
Finally, add the product details one by one into items .
Now, the main.go will look like,
package main
import (
"fmt"
"github.com/gocolly/colly"
"github.com/gofiber/fiber/v2"
)
type item struct {
Name string `json:"name"`
Price string `json:"price"`
ImgUrl string `json:"imgurl"`
}
func main() {
app := fiber.New()
app.Get("/scrape", func(c *fiber.Ctx) error {
var items []item
collector := colly.NewCollector(
colly.AllowedDomains("j2store.net"),
)
collector.OnRequest(func(r *colly.Request) {
fmt.Println("Visiting", r.URL)
})
collector.OnHTML("div.col-sm-9 div[itemprop=itemListElement] ", func(h *colly.HTMLElement) {
item := item{
Name: h.ChildText("h2.product-title"),
Price: h.ChildText("div.sale-price"),
ImgUrl: h.ChildAttr("img", "src"),
}
items = append(items, item)
})
collector.Visit("http://j2store.net/demo/index.php/shop") // initiate a request to the specified URL.
return c.JSON(items) //we return the extracted data to the client by calling the c.JSON(...) method.
})
app.Listen(":8080")
}
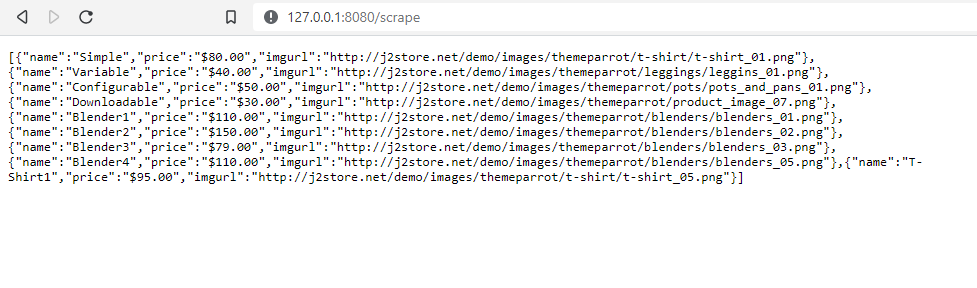
Now, run the command go run main.go and head to http://127.0.0.1:8080/scrape on your browser.
You'll see the data like the following,
Now, this data is from the first page but there are multiple pages on the site so we've to deal with all the pages. Colly Framework works very well with this. We need to add one more OnHTML callback for moving to the next page.
collector.OnHTML("[title=Next]", func(e *colly.HTMLElement) {
next_page := e.Request.AbsoluteURL(e.Attr("href"))
collector.Visit(next_page)
})
[title=Next] is the CSS selector for the Next button. You can see this by following the same way as did earlier. Now the URL added in the href tag is not an absolute URL, so we've used the AbsoluteUrl() function to convert the relative URL to an absolute URL.
Now, run the command go run main.go and head to http://127.0.0.1:8080/scrape on your browser.
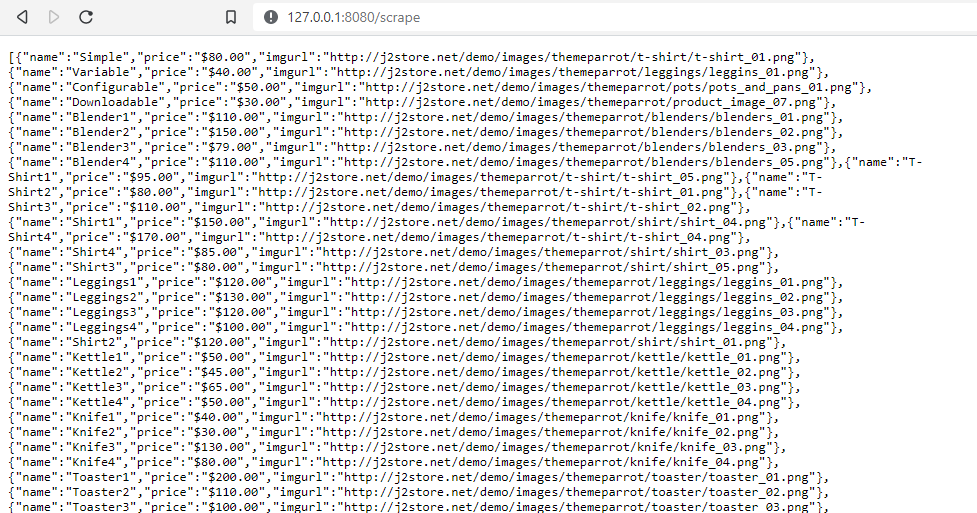
You'll see all product details from all the pages.
This is the basic implementation of a web scraper using the Fiber and Colly frameworks in Go
Conclusion
You can find the complete code repository for this tutorial here 👉Github.
Now, I hope you must have a solid foundation to build more complex and sophisticated web scraping projects. Now, you can try Scraping dynamic websites along with Data storage(SQL or NoSQL), Image and file download, Distributed scraping and so on.
Until then Keep Learning, Keep Building 🚀🚀



